
Case Study
Financial service recommendation system, This case study outlines a solution for developing a product recommendation engine for ABC Bank and utilizing Google Cloud Platform (GCP) Service and Vertex AI. The case study aims to personalize product recommendations for ABC Bank clients, suggesting relevant Direct Financing services, subsidies, advisory services, etc based on their needs.
Note: In this blog, I am only showing you all just an idea. in the follow-up blog, I will show how to implement this.
Case Study Overview
- Objective: Develop an intelligent product recommendation engine for ABC Bank.
- Target Products: Advisory service, Incubation Hub, Access to global, Access to the local market, Direct Financing, Credit guarantee, Training, Events, Awards, subsidies, etc services
- Business Impact: Enhance cross-selling, repeat business, and customer retention.
Solution Architecture
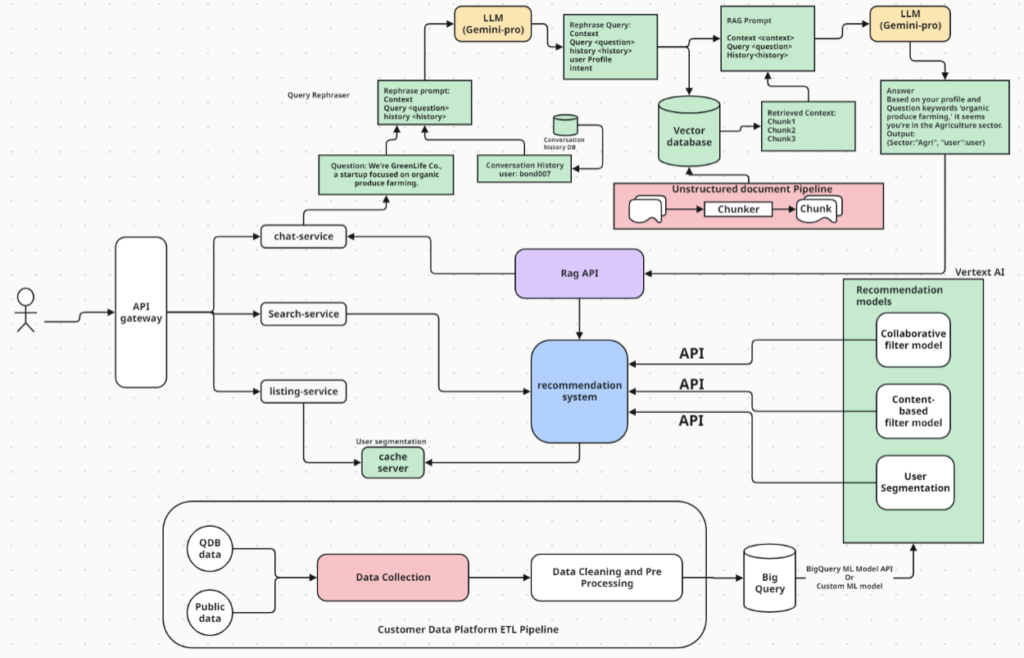
Fig-1
Building a Financial service recommendation system requires a lot of integration points beforehand to serve the customers. We required both cloud services as well as custom solutions.
There are 4 major components from the Fig-1
- Data Pipeline
- ML/Deep Learning Model
- RAG system with LLM
- Application Layer to serve request and response.
Google Cloud Platform (GCP Service)
- Big Query: For large-scale data storage and processing
- Vertext AI: For model training, Hyperparameter tuning, and model deployment.
- Cloud Storage: for storing training data and model artifacts.
- Cloud functions: For creating service workflows.
- Monitoring Tools: Monitor model performance and system health for continuous improvement.
Data Pipeline
Data Pipeline: Customer data platform ETL workflow is responsible for
- Data Collection: from ABC Bank data, industries data
- Data Cleaning: Clean and transform data
- Feature Engineering: Generate relevant features for model training.
For our Recommendation system, the input data consists of various features that describe customer interaction and their engagement with different services offered by ABC Bank.
Let’s take this example
Customer Transaction Data
| CustomerID | ServiceID | Engagement | Interaction date | Customer segment |
| 1 | S001 | 8 | 2024-05-21 | SME |
| 2 | S002 | 6 | 2024-05-22 | Startup |
| 3 | S003 | 9 | 2024-05-23 | SME |
| 4 | S004 | 5 | 2024-05-24 | Corporate |
| 5 | S005 | 7 | 2024-05-25 | Startup |
Service data
| Service ID | Advisory Service | Category | ||
| S001 | Direct Financing | Finance and Funding | ||
| S002 | Adisory Service | Develop Business | ||
| S003 | Investment | Finance and Funding | ||
| S004 | Credit guarantee | Finance and Funding | ||
| S005 | Incubation Hub | Develop Business |
Output
| Customer ID | Recommended Product | Success Probability |
| 1 | Direct Financing | 0.85 |
| 1 | Advisory Service | 0.75 |
| 1 | Investment | 0.65 |
| 2 | Adisory Service | 0.80 |
| 2 | Incubation Hub | 0.70 |
Model Development
We will observe How collaborative and content-based filtering helps to build a Financial service Recommendation system.
- Collaborative Filtering: Matrix Factorization Technique like SVD algorithm.
- Content-Based Filtering: TF-IDF model
Bigquery ML provides an out-of-the-box service to build this model on the given dataset. It will create a correlation matrix based on customer and product usability
Output: Predicted Ratings based on customer engagement on Products.
These are just hypothetical number ratings against each service.
| Customer ID | S001 | S002 | S003 | S004 |
| 1 | 3.98 | 3.45 | 4.13 | 2.45 |
| 2 | 3.56 | 2.88 | 3.89 | 2.22 |
| 3 | 4.25 | 3.67 | 4.45 | 2.87 |
Now if you get data from this matrix for customer ID 1
The output would be
For Customer 1:
- S003 (4.13)
- S001 (3.98)
- S002 (3.45)
- S004 (2.45)
Similarly, we can build a model around a content-based filter using the TF-IDF model and its term frequency-inverse document frequency.
Mode Pipeline and service

Fig-2
Performance Monitoring and Maintenance
Monitoring
- Track model performance with metrics like RMSE (root mean squared error) and MAE (mean absolute error)
Deep Learning Model:
We will build a classification model that predicts the likelihood of the customer choosing a specific product based on their engagement and other features. This model uses a deep learning approach using TensorFlow.
Vertex AI provides a service to build and deploy this model.
Components and Flow
- Model Training & Optimization
- Model Validation
- Model Deployment & Monitoring
Model Architecture
- Input Layer: Accepts the preprocessed feature data.
- Hidden Layers: Fully connected (dense) layers with ReLU activation functions to learn complex patterns in the data.
- Output Layer: Outputs probabilities for each product using a softmax activation function.
Input Features:
- CustomerID
- ServiceID (encoded)
- Engagement Level (scaled)
- InteractionDate
- CustomerSegment (encoded)
| CustomerID | ServiceID | Engagement Level | Interaction date | Customer Segment |
| 1 | Direct Financing | 8 | 2024-05-21 | SME |
| 2 | Adisory Service | 6 | 2024-05-22 | Startup |
| 3 | Investment | 9 | 2024-05-23 | SME |
| 4 | Advisory Service | 5 | 2024-05-24 | Corporate |
| 5 | Incubation Hub | 7 | 2024-05-25 | Startup |
Output Data
The output data from the model will be product recommendations for each customer, along with the success probabilities.:
| Customer ID | Recommended Product | Success Probability |
| 1 | Direct Financing | 0.85 |
| 1 | Advisory Service | 0.75 |
| 1 | Investment | 0.65 |
| 2 | Adisory Service | 0.80 |
| 2 | Incubation Hub | 0.70 |
- Recommended products with success probabilities
The step involves building a model using the Vertex AI:
- Upload data to cloud storage
- Create a Verext AI dataset
- Create a training job and run the job
- Deploy the model to the endpoint using the model upload service.
- Setup monitoring with stack driver service
These are the 5 simple steps that help us to build the model there are further steps for model tuning hyperparameters. We can use a cross-validation technique to tune the hyperparameter.
RAG Architecture
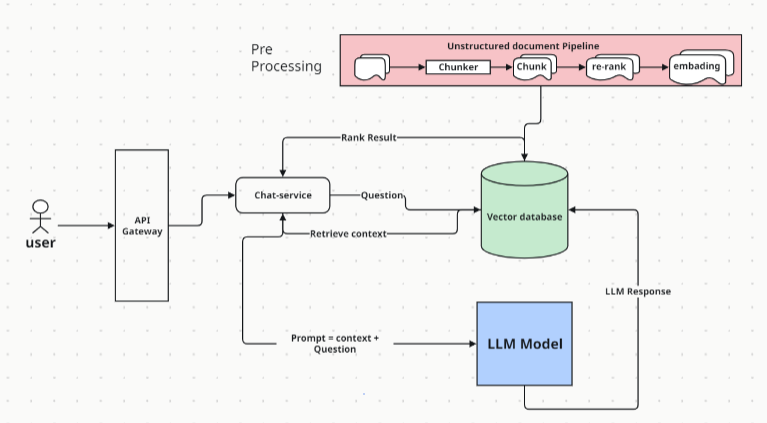
Fig-3
- Retrieval Augmented Generation (RAG) is an advanced AI technique that combines information retrieval with text generation, allowing an AI model (Transformer or BERT) to retrieve relevant information from a knowledge source and incorporate it into generated text.
- RAG enables LLMs to produce higher quality and more context-aware output.
- Essentially RAG empowers LLMs to leverage external knowledge to improve performance.
RAG Pipeline Steps
- The first step is to Convert the message and information into vector embedding.
- Store embedding to vector index database there are a lot of options available.
- Between These two steps, there are a few sub-steps like chunking, and rechinking in the Unstructured case.
- Retriever, Ranker, and generator are the three important operations that are performed.
- Retriever retrieves the context and the ranker provides a similarity ranking
User Flow with Recommendation System – ABC Service
Let’s take an example and try to understand what the user flow going to look like in the Financial service Recommendation system. Below we are going to see the chat service flow. there are two scenarios 1. Acquisition 2. Retention
Chat-Service flow
Scenario-1 (Acquisition)
User: FinServe company (get required detail first hand about the company in this case Finserve co, financial advisory company)
Objective: FinServe Co. visits the ABC application to explore new business opportunities.
System: Welcome
User: we are a financial advisory startup looking to expand our services.
System: The system uses RAG service API to get the context of this question. And sent a response based on the intent of the user.
Rag will generate required input to recommend services based on the engagement level and provide service recommendations. For example
our ‘Access to Global Market’ service can help you connect with international clients seeking financial advisory expertise.
Additional Recommendation
“Advisory Service” to get expert guidance. And also provides an “Incubation Hub” service which supports startups to scale businesses.
Note: based on the user question and interest system recommended 3 services in the following ranking order
- Access to the Global Market
- Advisory Service
- Incubation Hub
Scenario 2: Retention Scenario
User: SecureWealth Inc. (A wealth management company)
Objective: SecureWealth Inc. returns to ABC to explore additional services and support.
Used Service: Credit Guarantee
User: “We are looking to enhance our services and explore more funding options.”
System: Based on the historical service data. The system will retrieve the information of the user and service and send it to the recommendation service. Now users are already using one service we can fetch from the collaborative filter model to provide additional service recommendations. For example
related funding options such as ‘Direct Financing‘ or ‘Investment’?
User: Can I get more details about the ‘Direct Financing’ service?
System: use RAG API to get consolidated information related to Direct financing service. In addition, it will also use recommendation services to provide additional service details to users.
These are just examples of creating workflow-rich prompt engineering required in order to create a recommendation system.
Tech stack
- Language: Java, Python, SQL
- Libraries: BigQuery ML, Vertex AI service, Google Cloud service, Google Function, Spring Boot, Tensorflow, Scikit-learn, Panda, Numpy
- Technology: Data Pipeline, ETL, Deep Learning, Machine Learning, Generative AI, Prompt Engineering
Conclusion
The proposed solution leverages Google Vertex AI for training and deploying a deep learning model for product recommendations. The solution architecture integrates various GCP services, ensuring a robust, scalable, and efficient recommendation system that aligns with ABC’s objectives. This approach enhances customer engagement, drives cross-selling, and improves retention rates, providing significant value to ABC Bank.
Footnotes
Additional Reading
- AI vs ML vs DL vs Data Science
- Logistic Regression for Machine Learning
- Cost Function in Logistic Regression
- Maximum Likelihood Estimation (MLE) for Machine Learning
OK, that’s it, we are done now. If you have any questions or suggestions, please feel free to comment. I’ll come up with more Machine Learning and Data Engineering topics soon. Please also comment and subs if you like my work any suggestions are welcome and appreciated.